Привет! Подскажи, пожалуйста, суть этих ламп. И я так понимаю, что это уже не первоначальная задумка, а дополнение к действующему симулятору, так? Сейчас идея все та же или уже нет? Хотелось поподробнее объяснений) Какие еще идеи планируется реализовать? Смотрю, что-то движется! Успехов!
Игра проектируется под то, что люди сами смогут делать свои полигоны движения. Внутри не будет никаких "скрытых" кодов, которые жестко привязывают игру к полигону. К примеру, сейчас ты не можешь модифицировать data.dat, чтобы сделать выход с Сургута двухпутным, игра тебя "не поймет". Я же продумываю так, что игроки смогут делать вообще любой полигон какой захотят, игра сама должна будет разобраться как с ним работать. И игрокам может захотеться сделать "нетиповые" лампы на каких-то сложных станциях при недостатке места на Пульте. Это и было задачей: уметь работать с лампами любых конфигуаций на территории станции. Кроме того, это может позволить делать некие другие лампы. Скажем, сделать все лампы круглыми, как это типово сделано на станциях на пультах.
Добавлено (05.06.2023, 18:55) --------------------------------------------- Кроме того, сразу проектирую под то, что: 1. Игра может оперировать сразу двумя и более полигонами, между которыми будет происходить передача поездов. Т.е. в теории, можно будет переключаться между участками Тобольск - Демьянка, Демьянка - Куть-Ях, Куть-ях - Сургут, Сургут - НВ1 и тащить поезд с Тобольска до Лангепаса под выгрузку. 2. Игра должна позволять подключаться одному игроку к одному или нескольким полигонам, равно как и нескольким игрокам к одному полигону. 3. Игра должна позволять делать частичные отцепки/прицепки по пути следования сборного поезда.
Очень тормозит дело пока что недостаток знаний и то, что нет опыта как это должно правильно делаться.
Добавлено (06.06.2023, 22:28) --------------------------------------------- Оффтоп. Есть серьезное такое правило: "Нельзя озвучивать свои планы!" Работает, по видимому из того, что озвученные планы как бы дают неправильную инфу подсознанию, что 2задача сделала". А раз задача сделана, зачем ею заниматься? Подсознание сильно этому противится. В частном случае я с трудом заставляю себя дальше делать. Но обязан справиться со своим посознанием =)
Добавлено (07.06.2023, 09:04) --------------------------------------------- Оффтоп 2. Так как проект планируется большой, а предыдущая попытка окончилась неудачей, то я решил посмотреть, как делают большие проекты. А большие проекты, в том числе, по технологии TDD - https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5
В отличии от обычной разработки, в TDD прог _сначала_ пишет тесты, покрывающие будущий функционал, потом делает тестовый прогон, который должен кончится неудачей, так как функционала, по идее, нет. Но если он уже есть тест пройдет успешно, что будет считаться ошибкой разработки, надо будет разбираться.
После первого, неудачного, прогона теста, прог должен написать сам код, который (А) успешно скомпилируется; (Б) пройдет тесты. И далее на новый цикл.
Я почти не писал тесты, сейчас решил покрыть тестами метод загрузки BMP файлов - LoadBMP. Он сделан так, что в ошибочных случаях "крашится", вызывая исключение {try...catch...finally}, а в сообщении описывает причину краха. Причину видно в момент краха, но видно только в отладочном режиме. Однако, родной код языка, который грузит другие картинки, не крашится.Он не грузит и сообщает об этом. Но НЕ сообщает о причинах невозможности загрузки.
Возникает мысль переписать мой метод LoadBMP так, чтобы он тоже не крашился, но не грузился. А внутри запоминать причину невозможности загрузки строкой, чтобы другой код, который вызывал загрузчик, мог причину прочитать и пользователю показать (это задел на то, что другие пользователи будут делать свои полигоны).
А еще тест должен проверять все строки тестируемого кода, проходя по всем возможным комбинациям сбоев. Если у нас нет возможности загрузить картинку по 10 причинам, значит должно быть 10 тестов, которые проверяют эти 10 причин и, заодно, еще и проверяют строки, которые возвращает LoadBMP. Строки должны совпадать с причинами.
Но это значит, что строка должна дублироваться - в коде LoadBMP и в тестовом коде. А это некорретно, так как меняя строку в LoadBMP (что НЕ меняет код), нам надо поменять еще и в тесте, иначе тест "упадет".
Теперь у нас мысль, что строки ошибок, по одной на ошибку, должны лежать отдельно, а оба метода LoadBMP и TestLoadBMP должны их читать из одного файла.
И тут мы нарываемся на другую проблему. Файл со строками, строго говоря, должен быть в двух экземплярах.
Один экземпляр должен лежать в дереве исходного кода программы, чтобы его мог "подхватить и запомнить" обработчик distributed software configuration management system, в моем случае - это Fossil: https://fossil-scm.org/home/doc/trunk/www/index.wiki Использование его позволяет "откатиться" на нужную версию кода, если в разработке что-то уж совсем поломал. Кроме того, он же позвляет разрабатывать отдельные ветки кода (branch) независимо друг от друга, потом их объединяя при необходимости (merge) когда разработка части кода завершена. По требованиям Fossil, файл строк должен иметь кодировку UTF-8.
Второй экземпляр должен лежать в дереве компилированного кода, так как именно дерево комплированного кода потом будет рассылаться пользователям. А его кодировка должна быть ASCII.
То есть, при компиляции надо посмотреть образец в дереве исходников, взять его время модификации, сравнить с файлом в дереве компилированного кода. Если время не совпадает (мы поменяли файл в дереве исходников) скопировать образец из дерева исходников в дерево компилированного кода, по пути изменив с кодировки UTF-8 на ASCII. А этот перекопировщик мы должны (А) написать; (Б) написать к нему тестер. Причем, мы же TDD, поэтому сначала пишем тесты самому копиру-транслятору, потом его сам.
Но и тут проблема. В файле строк мы сохраняем обычные строки, типа "Выходной буфер слишком мал!" Но в коде есть сложные строки, типа такого:
"По метаданным буфер должен быть " + ХХХ + " байт, но подан буфер " + YYY + " байт".
То есть у нас три строки, которые "склеиваются" в одну, подставляя вместо переменных величин XXX и YYY их строковые представления. Получается типа "По метаданным буфер должен быть123456 байт, но подан буфер 11111 байт".
Пока мы дублировали строки в тестируемом коде и в коде тестировщика, это была рабочая схема. Но теперь у нас должна быть _одна_ строка на проблему. Как решается эта проблема в промышленном софте? Решение называется "форматная строка", как это, для примера, в Питоне: https://skillbox.ru/media/base/formatirovannye-stroki-v-python-primery-ispolzovaniya/ Предыдущий вариант должен выглядеть примерно так: format("По метаданным буфер должен быть {} байт, но подан буфер {} байт", XXX, YYY). Теперь у нас строка одна, но появился "форматтер", который должен "разобрать" строку и подставить вместо "{}" соответствующие параметры).
Но там, где я пишу, такого механизма, форматтера, нет! Его тоже надо написать. И, бинго, тоже покрыть тестами!
И все это в сумме ни на грамм не приближает к продвижению разработки симулятора.
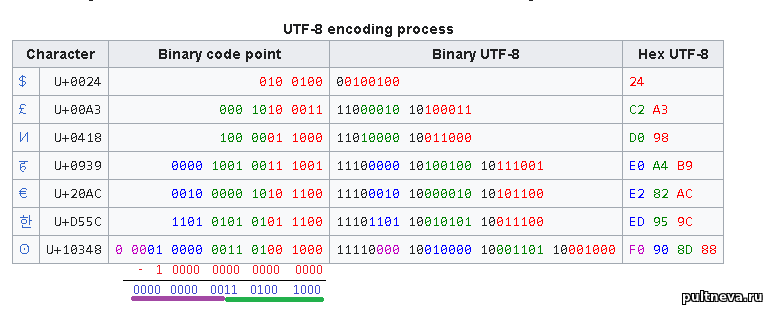
Добавлено (10.06.2023, 05:24) --------------------------------------------- Пока встал на проблеме декодера, который должен utf-8 превратить в ASCII. Там проблема в том, что нужно заиметь два файла одного текста: UTF-8 и UTF-16. А из UTF-16 ASCII делается элементарно. Но чтобы получить корректные символы нужных диапазонов для теста, я пишу файл-образец UTF-32. По замыслу, из него получаю UTF-8, из него - UTF-16, а потом при тестовом декодировании сверяю корректность UTF-8 и UTF-16.
Ок? Ок! Проблема в том, что я не смог найти тулз, чтобы из UTF-32 получиить UTF-8. Онлайн-трансляторы работать не хотят, в Notepad++ поддержки UTF-32 нет. Пока тупик.
Нашел выход в том, что ... просто взял контрольные цифры с википедии! =) https://en.wikipedia.org/wiki/UTF-8#Encoding_process имеет табличку со значением и байтов UTF-8, и значений UTF-32. То есть, я взял и написал декодер UTF-8 в UTF-32 пользуясь этими значениями как опорным данными.
Ок, сделал конвертер UTF-8 в UTF-32. Далее по плану у нас конвертирование UTF-32 в UTF-16. Тут проблема в том, что максимальное значение UTF букв = 0x10ffff, а максимальное значение, которое хранится в utf-16 - 0xffff.
Разработчики сделали так: Если буква > 0xffff, то есть в пределах 0x10000 .. 0x10ffff, то мы вычитаем из буквы 0x10000. Получили значение в диапазоне 0x00000 .. 0xfffff. То есть - 20 бит. Далее эти двадцать бит драконим по 10 и пакуем в две шестнадцатеричные буквы. И обзываем эти буквы "суррогатами" (surrogate). Старшие 10 складываем с 0xD800 и получаем диапазон 0xD800..0xDB00. Младшие складываем с 0xDC00 и получаем диапазон от 0xDC00 по 0xDFFF.
К чему все эти описалова? Т.к. я кодировал разбор UTF-8, то далее я просто сохранил UTF-8 представление в файл, файл открыл в Notepad++, там рекодировал в UTF-16 и записал. Потом открываю его в hexed.it и вижу бинарные данные. Интересный момент выделил синим. Переношу внутрь тестера в массив. Пишу код кодера, все хорошо, отрабатывает прям идеально. Сохраняю код в fossil и смотрю на сохраненнку. И тут глаз цепляется за явную ошибку:
Я должен был число сдвинуть на 10 бит, потом оставить только сдвинутые биты, очистив лишнее (& 0x3ff) и сложить с 0xd800. Но палец слишком задержался на нуле и получилось два нуля. И сдвиг делается на 100 бит. А это означает что любой аргумент будет обнулен так как общая длина аргумента не более 32 бит вообще. Чтобы там ни было передано, на выходе получится ноль плюс 0xd800 = 0xd800.
Начал разбираться, почему не сработал тест? Что получилось? А то, что в разделе википедии в UTF-8 в длинный параметр взяли слишком низкое значение. После вычитания 0x10000 (на скрине в двоичных данных), старшие 10 бит равны нулю (подчеркнуто фиолетовой линией). Как ни двигай ноль, в результате - ноль. Ноль плюс 0xD800 = 0xD800. Что и получилось выше по скринам. Т.е. ошибка точно "легла" на ошибочный аргумент и прога считала неправильно, но изза ошибочного аргумента эта ошибка была не видна! Тест прошел, оно бы все осталось в проге и где и когда бы вылезло в виде ошибки - Бог знает!
Добавлено (10.06.2023, 18:07) --------------------------------------------- 1. Сделать форматтер 2. Сделать раскодирование utf-8 в utf-32 3. Сделать перекодирование utf-32 в utf-16 ---- мы находимся тут ----- 4. Сделать перкодирование utf-16 в ASCII 5. Сделать файлы строк в utf-8 (изза Fossil) в дереве исходников 6. Сделать помощник комплитора, которые берет файл из дерева исходников и копирует их в выходное дерево попутно перекодируя по пути utf-8 -> utf-32 -> utf-16 -> ASCII. 7. Сделать загрузку ASCII файла из выходного дерева. 8. Обвязать тестами LoadBMP сделав привязку строк из загруженного файла.
И все это чтобы можно было посмотреть, что не так при загрузке проблемного BMP файла если его не удалось грузаность, сообщив пользователю.
Добавлено (11.06.2023, 19:45) --------------------------------------------- 1. Сделать форматтер 2. Сделать раскодирование utf-8 в utf-32 3. Сделать перекодирование utf-32 в utf-16 4. Сделать перкодирование utf-16 в ASCII 5. Сделать файлы строк в utf-8 (изза Fossil) в дереве исходников 6. Сделать помощник комплитора, которые берет файл из дерева исходников и копирует их в выходное дерево попутно перекодируя по пути utf-8 -> utf-32 -> utf-16 -> ASCII. ---- мы находимся тут ----- 7. Сделать загрузку ASCII файла из выходного дерева. 8. Обвязать тестами LoadBMP сделав привязку строк из загруженного файла.
Добавлено (11.06.2023, 23:02) --------------------------------------------- Спустя 7 часов 40 минут и 761 строку кода вышеприведенная задача закончена. Было несколько прикольных глюков на которых убил много времени. 1. Есть тестовая функция, которая вызывает тестируемую. Тестовая вызвает, тестируемая отрабатывает, возвращается в тестируущию. Отрабатывает с ошибкой. Не смотря на то, что ошибку в тестируемой я исправил. Ошибка не уходит. И так и эдак - не уходит. Уже начинаются приколы типа "вывести строку в консоль, что мы вошли в тестируемую функцию!" Вывода нет! Чую, что медленно схожу с ума. Куда-то уходит, где-то работает, работает с ошибкой, но не там, где я сижу. Причина в том, что тестируемая функция перемещелась в процессе работу в другое место в дереве каталогов. И создала выходной бинарный файл тоже в другом месте. А старый бинарник остался. И тестировщик уходил и проходил со старым бинарником, в кортом была ошибка. А новый бинарник тестировщик не видел. 2. Тестовая функция вызывает тестируемую. Тестируемая сообщает, отработала она с успехом или нет. А далее я в тестировщике я делаю глупую ошибку типа такого
Цитата
success = CompilerSupport(...) if (success) { // проверяем, что он отработал хорошо, сверяя данные } else { }
То есть, я чет решил, что всегда получу "success"(успешно) и сделаю пост проверку. И если на пост проверке будет что-то криво, пост-проверка мне все сообщит.
А я получал не-успех. И в пост-проверку не входил. И сообщений никаких не видел. И думал, что все тесты проходят. А там писалась всякая неадекватная хрень. И тест этого не видел! Потому что я поленился вставить "вопли Видоплясова" в ветку "не-успешно".
Добавлено (18.06.2023, 15:43) --------------------------------------------- Сделал автогенератор. В некоторых ситуациях, файл с сообщениями об ошибках будет не доступен программе, поэтому нужно в момент компиляции подставить нужные строки ошибок прямо в исходных код программы. Эти строки будут использоваться если невозможно загрузить внешний файл. Автогенератор наблюдает, что поменялся файл с сообщениями ошибок и делает две вещи:
Копирует в дерево бибилотек, конвертируя из UTF-8 в Latin-1
Имплементриует кодированные данные в Latin-1 прямо в исходный код (текст) библиотеки.
А исходный код после комплируется компилятором и попадает в библиотеку.
Добавлено (20.06.2023, 17:48) --------------------------------------------- Полностью закончена задача, которую зачал 07.06 (две недели назад): полностью покрыт тестами LoadBMP и сделана система сообщений об ошибках. Эта задача сдается в архив и теперь в планах возвращаться уже к самому симулятору.
Добавлено (20.06.2023, 18:04) --------------------------------------------- в проекте щаз 3700 строк кода
Ощущение трясины никак не пропадает. Вся инфа об участке хранится в Territory\1\data.dat (Territory\2\data.dat).
Этот файл читает подсистема "Модель"(Model, отсылка на "модель мира"). Именно в ней должны обсчитываться поезда, сигналы, положение стрелок и т.п. Модель сообщает об изменениях Представителю("Presenter"), который, в свою очередь, управляет Демонстратором("View"). Или, другими словами, у меня реализуется паттерн программирования Model-View-Presenter (MVP).
В начале разработки я разрабатывал без тестирования. С 07.06 я перешел на режим TDD(гуглить Test Drive Development). У меня грузилась модель частично, только инфа по станциям. Сейчас начинаю добавлять перегоны. Ну и встреваю сходу двумя ногами в трясину. В файле data.dat перегоны лежат в разделе Data_Graph_Peregon
Прога ловит начало раздела и... И что надо сделать первым делом? Скинуть пустые строки. Вот эти все строки с ";"(точками запятыми) считаются "пустыми строками". Не-пустая строка начнется там где 1, 2,...
Но! Файл может быть бракованным и при "скидывании" пустых строк мы можем "дойти" до конца. Это ошибка, и там есть и проверка на ошибку и сообщение. Ок! Но у меня же TDD, да? А значит в тестах я обязательно должен зайти в эту возможность чтобы проверить что загрузка Модели отлавливает эту ошибку. А значит, файл data.dat надо "портить". Буквально, отрезать все, что там идет дальше, после заголовка секции. И рестартануть разбор.
Но если так сделать и произойдет где-то ошибка, файл НЕ вернется в нормальное положение, он останется обрезанным. Значит, что? Надо научить Модель грузить файлы с другими именами. Тогда мы берем родной data.dat, режем его и сохраняем как копию. И копию посылаем в Модель. И смотрим как себя ведет Модель. Значит надо переписать модель на возможность загрузки других файлов. Но раз уж взялись переписаться на возможнсоть загрузки, то сходу надо предусматривать, что так-то у нас глобальные идеи. Возможные режимы игры: 1. Игра на компе пользователя. Читаем родные файлы. 2. Игра на компе пользователя, но модель на другом компе. Т.е. "онлайн-игра по сети". Модель читает/пишет как файлы, так и данные в базу данных, находясь на сервере. Возможно, по соображениям безопасности вообще не будет доступа к файлам и надо будет читать/писать в базу данных. 3. Игра на компе пользователя, модель на компе пользователя, но файлы находятся на другом компе, на некоем сервер. "Одиночная кастом-игра".
То есть, сходу надо выносить чтение/запись в отдельный интерфейс и работать с ним. А значит надо писать: 1. Файл интерфейса; 2. Файл адаптера интерфейса; 3. Файл сообщений ошибок. 4. Файл обработки ошибок. 5. Тест-файл адаптера интерфейса 6. Тест-файл обработки ошибок.
Утешает только то, что у меня в проге сейчас файлы читаются в куче мест самым "мусорным" образом. Данное изменение позволит потом отрефакторить код и сделать все "единообразно-красиво".
Добавлено (23.06.2023, 13:26) --------------------------------------------- В проекте 4258 строк кода, сидим в трясине.
Добавлено (25.06.2023, 16:36) --------------------------------------------- Сделал загрузку перегонов. Решил пока не настраивать отображение пока не загружу все данные вообще. Т.е. далее полная загрузка в планах. ps. По прежнему не получается писать тесты ДО того как я сделаю код. Но надо исправится.
Добавлено (26.06.2023, 15:52) --------------------------------------------- В проекте 4706 строк кода
Добавлено (26.06.2023, 20:54) --------------------------------------------- Сильно дико не хватает знаний. Сейчас встал на перепутье по вопросу - "Делить ли данные по станции на два объекта - для Модели и для Демонстратора или хранить все данные в одном объекте?" Вопрос возник из-за того, что файл данных data.dat читает модель. Которая формирует, на данном этапе, данные для Демонстратора, как том правильно "отрисовать" станцию. Но теперь я подхожу к разбору секции ламп файла data.dat и возник вышеупомянутый вопрос. То ли расширять структуру данных добавляя сведения о лампах, структуре путей станции, поездах на станции, движении резервных локомотивах по стации. То ли делить это все на разные объекты-структуры: разные для модели и для демонстратора. В модели хранить сведения "окружающего мира", на основе этих сведений модель будет двигать поезда. А сведения как отображать на экране станции хранить в другом объекте, предназначенном для Демонстратора. Но если делить сведения на два объекта, то как их координировать между собою? Вопросы, на которые пока у меня нет ответов...
Добавлено (27.06.2023, 10:55) --------------------------------------------- Удалось найти описание всех лампочек пульта: https://studfile.net/preview/5412484/page:8/ Класс! теперь понятно что и как можно прогать. А то они были для меня серьезной загадкой.
Добавлено (28.06.2023, 14:24) --------------------------------------------- Еще и Zork сильно помог, скинув инфу по лампам. Живем!
Добавлено (29.06.2023, 21:12) --------------------------------------------- Изза болезни пока все остановилось. =(
Добавлено (02.07.2023, 06:34) --------------------------------------------- Столкнулся с резким нарастанием времени тестирования. Каждая "ошибка" в data.dat должна быть обработана, а для этого data.dat модифицируется и рестартится к разбору. А каждый разбор съедает по 0.2 секунды времени (примерно). Десять тестов - минус 2 секунды на тест. Планируется: 1. Немного изменить алгоритм загрузки, чтобы загрузка шла в таком порядке: А) грузятся все фрагменты "вразнобой"; Б) и только после загрузки всех фрагментов начинаем "связывание" т.е. настройку связей между загруженными фрагментами.
2. Тесты проводить "по-фрагментно". Т.е. из оригинального data.dat "вырезать "фрагменты" и их тестировать отдельно. Это позволит резко сократить масштабы обработки на каждом тесте. 3. И только на финальном тесте проводить полную загрузку для проверки контрольных соотношений.
В проекте сейчас 4935 строк кода.
Добавлено (02.07.2023, 14:49) --------------------------------------------- Потратив ровно два часа программирования и 174 строк доп.кода у меня появилась возможность проводить тесты по-объектно. Теперь тест занимает не 2 (две) секунды(!), а 0.5 секунд(!). Экономия на тесте - 1.5 секунды. За два часа работы.
Добавлено (02.07.2023, 19:00) --------------------------------------------- За каких-то дополнительных 110 минут у меня добавился файловый интерфейс, работающий с оперативкой. Теперь модель при загрузке загружается из памяти, исключается запись/чтение с/на диск. Что позволило сократить тест на грандиозные 0.2 секунды: вместо 0.55 секунд тест проходит за 0.35 секунд ps. В проекте 5471 строк кода.
Добавлено (03.07.2023, 03:13) --------------------------------------------- За "каких-то" еще 104 минуты программирования удалось снизить время теста с 0.35 до 0.14. Но самое убойное ждало меня во время последнего забега. Я вспомнил, что Модель при загрузке сначала грузит pult.bmp, а потом начинает грузить data.dat. И потом, в тесте, на data.dat она и "падает" контролируемо. Но на загрузку pult.bmp тратит 0.1 секунды на каждый тест из группы тестов. Перенеся загрузку pult.bmp в конец, я смог сходу улучшить общее время теста с 1.9 секунды до 0.7 секунды. т.е. можно было вообще ничего не делать по тем переписываниям что я тут весь день делал, просто перенести в конец загрузку pult.bmp. Это весьма сильно меня расстроило.
Пока что доделана секция загрузки лампочек. Грузится 210 строк из 2450 строк файла data.dat. В проекте сейчас 5545 строк кода.
Добавлено (07.07.2023, 22:16) --------------------------------------------- Потрачено 60 минут и 220 строк кода модуля Теста и 102 минут и 98 строк кода загрузилась секция Data_Sekz из файла data.dat.
В этот раз тренировался по другому немного. Сначала поставил себе задачу написать ВСЕ тесты. И только потом писать сам код, который должен успешно тесты отработать. Такая задача произошла из прошлой секции загрузки лампочек: я написал первые тест и начал писать код в модели (загрузчике). И выяснил, что надо написать почти весь код загрузчика, чтобы добраться до первого теста. Т.е. я как бы опередил разработкой написание тестов.
В этот раз я писал тесты, там тоже были некоторые сложности. Пусть мы пишем первый тест. Его надо запустить, отладить. Он запустит Модель. Модель тест "не пройдет" ибо Модель еще не написана. Ок, переходим ко второму тесту... Но при попытке отладки теста №2, тест №1 просто не дает дойти до теста №2, он туда не пускает. Простейшая задача почему-то заставила почесать репу. В итоге простое решение: просто комментируем строку в тесте №1 которая вызывала останов. Потом делаем тест №2, там проверяем, комментим и так до конца. (upd. Разумеется, как написаны и оттестены до конца сами тесты, все комменты удаляем)
Список тестов (на память, могу пропустить): 1. После тега [Data_Skez] нет ничего (это ошибка). 2. а Неправильное первое число 2. б Неправильное второе число (там числа парами идут). 3. Непарное число (первое число есть, второго до конца строки нет), после первого числа есть запятая. 4. Непарное число, после первого числа запятой нет. 5. Второе число FFFFh (65535) (это ошибка). 6. Среди первых чисел нет FFFFh (65535) (отсутствует признак останова разбора / признак конца секции).
Пришлось помучиться еще и в том, что я решил, что раз уж число не разобралось, то в ошибке его вывести. В итоге пришлось помучиться так как разборщик у меня не возвращает ошибочную строку. В итоге код задублировался: 1. Я сначала выделяю строку 2. Потом отправляюсь в разборщик номера, который снова выделяет строку и пробует ее разобрать, превратив в число. 3. Если это не получается, я сохраненную в п.1 строку добавляю в текст ошибки.
То что можно переписать сам разборщик, мне чет в голову не пришло. А там ошибочная строка выделяется при разборе; ее, стркоу, достаточно вернуть по запросу.
За "каких-то" еще 104 минуты программирования удалось снизить время теста с 0.35 до 0.14.
При загрузке грузятся файлы data.dat & pult.bmp. Но если мы "выпадаем" по ошибке то мы гарантированно "выпадем" на моменте загрузки data.dat. В такой ситуации есть замысел отложить загрузку pult.bmp. Однако устройство загрузчика файлов из памяти требовало предварительной загрузки в память с диска в момент запуска тестовой функции Модали так как иначе ошибка будет уже в самой Модели в момент, когда Модель затребует себе pult.bmp.
Был переписан загрузчик таким образом, чтобы осуществлять "ленивую загрузку" (lazy-loading). Теперь если мы вываливаемся на ошбке в момент тестирования Модели, мы не грузим pult.bmp. Время тестирования сократилось с 0.14..0.15 до 0.06 секунд (в среднем).
Сейчас гружу секцию Data_Stanz, там какое-то нереальное количество проверок надо сделать. В данный момент в проекте 6498 строк (плюс 900+ строк в сравнении с данными от 07.07.2023)
Добавлено (10.07.2023, 11:57) --------------------------------------------- В проекте 6769 строк кода. В сравнении с данными от 07.07, добавлено 1224 строки кода (суммарно).
Это окончаниие загрузки секции Data_Sekz и загрузка Data_Stanz. чтобы понять, насколько большая секция Data_Stanz, я просто скопирую с data.dat:
На эти двенадцать строчек data.dat было убит 5.5 часов программирования и что-то около 1000 строк кода. В момент загрузки секции Data_Stanz проводится 20 (двадцать!) разного рода проверок на валидность данных. Тесты заняли 533 строки кода, код загрузки - 111 строк, и еще добавки это разного рода оптимизации типа "ленивой загрузки" из предыдущего поста.
Добавлено (13.07.2023, 00:17) --------------------------------------------- Начал грузить секцию Data_Gorl_Stanz (вроде так). Создаю структуру хранения загруженных данных. Выбираю длину short (короткие числа) для чисел так как не требуется больше.
А дальше начинается цирк. При создании объекта структуры нужно проверить, что поданые данные по крайней мере не отрицательные и не превышают ограничения констант. Это первая группа проверок. Они проводятся внутри структуры.
А при чтении мы читаем числа в числа в int из data.dat. А числа int длинней в разрядах. А просканировав и прочтя значения, мы должны проверить сканированные значения на то, что они не превывашают органичения, так как преобразование из int в short могут привести к самым удивительным результатам. Пример кода:
Цитата
int a = 983041; int b = 983040; int c = 983039;
short aa = (short)a; short bb = (short)b; short cc = (short)c;
Создаем три переменные a, b, c и присваемвае указанные значения. А потом их присваиваем значениям типа short, без контроля. АА будет равно... 1! BB = 0. СС = -1.
Поэтому у нас вторая группа проверок, что int числа могут "влезть" в short.
И потом будет третья группа проверок когда будет проводится связывание (linking).
Всё это предельно неэффективно по затратам времени программирования.
В итоге пришлось принять решенеи, что хранить данные сразу в int. Это удлиняет структуры, но сокращаются разные проверки. Вторая группа проверок просто исчезает.
Добавлено (13.07.2023, 17:50) --------------------------------------------- Смена парадигмы ускорила работу. Затраты времени по написанию кода по загрузке следующей секции Data_Gorl_Stanz затратили 2.8 часа в сравнении с предыщуей секцией - 5.5 часов, это ускорение в два раза. В проекте ≈7200 строк.
Добавлено (13.07.2023, 18:15) --------------------------------------------- ах, да! Грузится 275 строк из всего 2542 (т.е. 10.81%). Т.е. 2.8 часа программирования "ушло" на загрузку 34 строк.
Добавлено (13.07.2023, 18:18) --------------------------------------------- Хотя, если сравнить с пред секцией, это там было хлеще: 5,5 программирования на 19 строк.
ps. В теории, если дописать загрузку еще 4х секций, то можно уже линковать и начинать писать движение. Далее будут названия станций, графики движения поездов и т.п.
Добавлено (14.07.2023, 08:01) --------------------------------------------- Посчитал, скок секций data.dat осталось загрузить?
[Data_Put]
[Data_Str]
Data_Gr_Str]
[Data_Sl_Sekz]
[Data_Man_Svet]
[Data_Marsh_P]
[Data_Marsh_M]
[Data_Spar_Gr_Str]
[Data_Ost_Lok]
[Data_Peregon]
[Data_Graf_Pass_Ch]
[Data_Graf_Pass_N]
[Data_Graf_Gruz_Ch]
[Data_Graf_Gruz_N]
[Data_Podhod_Form]
[Data_Num_Poezd]
[Data_Plan_Form]
[DataS_RP_Name_Mnem]
[DataS_RP_Name_Manip]
[DataS_Stanz_Name
20 секций. Если на кажду будет затрачено по времени, скажем, 3 часа, то это 60 часов программирования.
Сообщение отредактировал V9 - Пятница, 07.07.2023, 22:17
На [Data_Put] потребовалось 4 часа программирования, в проекте 8036 строк кода (+836 строк к данным от 13.07)
Постоянно проявляются новые моменты, которые требуется учитывать.
ps. Вот такие картинки вырисовываю прямо в коде:
Добавлено (26.07.2023, 20:13) --------------------------------------------- Разработка была приторможена так как конец второго квартала, много отчетности и т.п.
Сегодня правил утилитную часть и делал то, что называется Incremental Compiler ( https://en.wikipedia.org/wiki/Incremental_compiler = ИК)
Раньше у меня было три запуска, что заставляло три раза грузиться движок: 1. ComilerSupport проверял смену .properties файлов и делал копировали переделку в исходники если .properties поменялись. 2. Компиляция. Занимало в среднем 1500 мс на каждый запуск. 3. Тест. В зависимости от того, полный это тест или некий субтест, изначально это было 2000 мс на запуск.
Эпопеей от 02.07..10.07 время тестирования было сокращено до 850 мс (полный тест) и до 60 мс (если у нас тест только успешный некоего фрагмента Модели).
А теперь инкрементальный компилятор(ИК) у меня компилирует за 15 мс. Т.е.полный цикл 1 + 2 + 3 занимает около 75 мс. Запуск теперь тоже из одного места, а не три раза подряд.
Изза этого были переписаны конфигурационные файлы, а от них пришлось и переписать счетчик строк кода в проекте. Облегчилось дело и в том, что теперь конфигурационные файлы не надо править как это было ранее при добавлении новых сущностей: ИК сам их находит и создает.
В данный момент в проекте 8545 строк кода,а процудера введения инкрементального компилятора затратила 146 минут.
Игра проектируется под то, что люди сами смогут делать свои полигоны движения.
Прочитал, но мало что понял. Я правильно понимаю что игрок может выбрать любой участок для создания, например Санкт-Петербург - Новый Петергоф, или это все те же грабли с сургутом без возможности что то поменять, ну разве ч то кроме наверно выхода на другой участок? Простыми словами скажи , что будет ( должно быть ) в итоге, без подробностей в кодах и прочим. Чисто тупо для пользователя вот это можно вот это нет.
Прочитал, но мало что понял. Я правильно понимаю что игрок может выбрать любой участок для создания, например Санкт-Петербург - Новый Петергоф, или это все те же грабли с сургутом без возможности что то поменять, ну разве ч то кроме наверно выхода на другой участок? Простыми словами скажи , что будет ( должно быть ) в итоге, без подробностей в кодах и прочим. Чисто тупо для пользователя вот это можно вот это нет.
Игра проектируется так, что игроки(пользователи) сами смогут проектировать и добавлять участки пути, настраивать расписания и т.п. Поэтому там все ошибки загрузки полигона тщательно "разжевываются" и всё-всё объясняется.
ЦитатаVATS ()
И можно ли будет, например, указать смену "километража" на участковых станциях, и типы локомотивов с их сменой?
Да.Но для начала надо хотя бы сделать как у Zork.
Цитатаisaewvlad2016 ()
Привет. Как успехи с симулятором? Есть продвижения?)
2 месяца не делал, сегодня продолжил, закончил один из множества кусков.
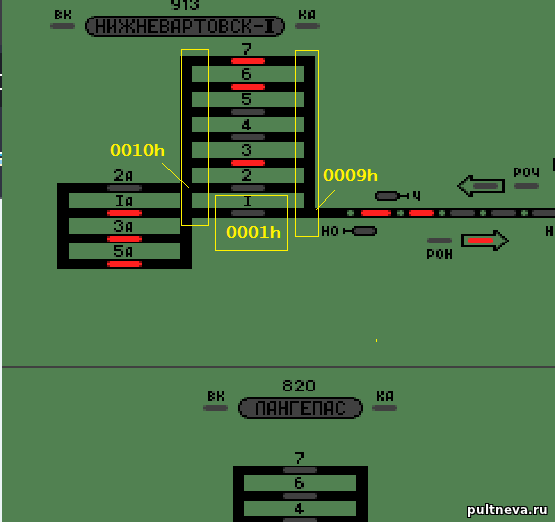
При обработке загрузки секции data.dat [Data_Sl_Sekz] потребовалось разобраться в именовании групп стрелок. Если кому интересно, вот так "внутри игры" выглядит Нижневартовск-1: Как как бы "групповая" стрелка в центре станции, куда стягиваются все пути обоих парков и плюс тупик для выставления(уборки) грузовых поездов. У пассажирского парка есть свой отдельный тупик, и, что интересно, его можно задействовать. Для этого можно сгенерировать грузовой поезд (он встанет на тупик 04h), он начнет заезжать в грузовой парк; и тут же сгенерировать локомотив, поставив задачу "выставить в пассажирский парк". Локомотив будет сделан в тупике 13h и заедет в пассажирский парк.
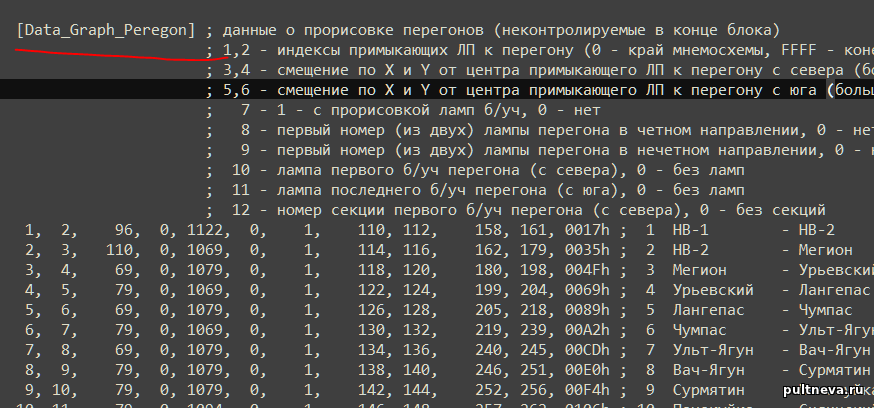
Добавлено (20.11.2023, 19:03) --------------------------------------------- Как "Буриданов осел" встал на такой проблеме. В data.dat граф всех путей и стрелок хранится в секции Data_Sl_Sekz:
[Data_Sl_Sekz] ; данные о следующей секции, длине, светофоpе для Ч и Н напpавлений и скорости ; 1 - нечетное направление - номер стрелки (0 - нет, >100 группа стрелок) ; 2 - нечетное направление - cледующая секция или блок-участок прямо (0 - нет) ; 3 - нечетное направление - cледующая секция или блок-участок набок (если есть стрелка, 0 - нет) ; 4 - четное направление - номер стрелки (0 - нет, >100 группа стрелок) ; 5 - четное направление - cледующая секция или блок-участок прямо (0 - нет) ; 6 - четное направление - cледующая секция или блок-участок набок (если есть стрелка, 0 - нет) ; 7 - длина прямо (0 - нет) ; 8 - длина набок (если есть стрелка, 0 - нет) ; 9 - номер лампы повторителя светофора Н (0 - нет) ; 10 - номер лампы повторителя светофора Ч (0 - нет) ; 11 - cкорость прямо пасс (0 - нет) ; 12 - cкорость прямо груз (0 - нет) ; 13 - cкорость набок (если есть стрелка, 0 - нет) ; (количество строк должно соответствовать количеству секций в 5-й строке) 0, 0010h, 0, 0, 0009h, 0, 1000, 0, 608, 271, 40, 40, 0 ; 1 0, 0010h, 0, 0, 0009h, 0, 1000, 0, 608, 271, 25, 25, 0 ; 2 0, 0010h, 0, 0, 0009h, 0, 1000, 0, 608, 271, 25, 25, 0 ; 3
......
Если я сделаю загрузку, то можно почти сразу выпускать "начальный релиз" для тех, кто будет делать свои диспетчерские участки. Потому как главное в симе — это как раз граф путей и стрелок. Пока люди делают и тестируют граф путей, я дописываю другие участки кода, другие секции и делаю остальное по игре.
И тут я встреваю в то, что как раз здесь надо писать все ошибки по графу путей, а значит надо сделать а) епическое количество проверок; б) по каждой проверке сделать разъясняющее сообщение; в) ко всему этому сделать возможность еще и возможность сообщения сделать на русском (у меня все сообщения на английском). Все красиво, но долго.
Или же можно забить на все ошибки, сделать разбор только минимального состава ошибок, забить на русский язык, а если кому-то что-то из "разрабов" будет непонятно, они смогут написать мне. Это позволит быстрей выпустить первый релиз.
Для этого можно сгенерировать грузовой поезд (он встанет на тупик 04h), он начнет заезжать в грузовой парк; и тут же сгенерировать локомотив, поставив задачу "выставить в пассажирский парк". Локомотив будет сделан в тупике 13h и
А можно ли сгенерировать вместо локомотива грузовой поезд и из 13 тупика отправить его (по готовности) в сторону НВ-2 и далее по маршруту?
Файл data.dat расположен в каталогах Territory\1 и Territory\2 и в них описаны участки Сургут—НВ1 и Куть-Ях—Сургут соответстенно. Редактирование этих файлов позволяет в возможных пределах модифицировать игру Zork'а. Файл в кодировке Windows-1251, перенос строки - 0x0d, 0x0a.
Сейчас поговорим о заголовке файла.
В заголовке 12 строк:
Цитата
1 ; участок Сургут - Нижневартовск 12 ; кол-во контролируемых линейных пунктов (ЛП) 34 ; кол-во стрелок (включая 2 стрелки по Ингуягуну, 4 по Покачево и 5 для тупиков по разъездам) 19 ; кол-во групп стрелок участковых станций (включая нулевую) 0180h; кол-во секций 1 ; 1 - серый фон в ГИД/НГДП, 0 - белый 7 ; высота в пикселях на 1 км перегона в ГИД/НГДП 21 ; перерисовка ГИДа: с какого часа остаётся кусок с предыдущих суток 3 ; -""- в каком часу стирается кусок с предыдущих суток 2012 ; за какой год набит ГДП 3 ; минимальное время на расформирование в часах (не менее часа) 5 ; максимальное время на расформирование в часах (на час и более минимального времени)
Первая строка - участок игры. Должен совпадать с каталогом, где расположен сам файл data.dat. Попытка исправить ведет к ошибке.
Вторая строка - количество станций, которыми игрок управляет на экране. В данном случае — 12. На экране для манипуляций они могут вызываться по клавишам F1..F12. Станции должны пролегать на одной линии жд линии, в игре у Zork нет возможности сделать "развилку". И вообще, там много кода который обслуживает станции без информации из data.dat. Поэтому невозможно удалить Лангепас, как пример.
Третья строка - количество стрелок в игре. Тут много интересных особенностей.
Стрелки бывают обычные с индексами от 1 до 99, групповые — 100..199, и, не знаю как называть - "сложно-групповые" — 200..299. Всего: 99 + 100 + 100 = 299 стрелок.
Вот это число из заголовка — это число, которое контролирует обычные стрелки. Если мы удалим сохраненнку save.sav, мы сможем поправить "34" из заголовка на "29" и игра спокойно запустится. Почему? Потому что обычных стрелок всего 29 — от первой до 29й. И только он проверяется. Показатели же групповых и сложно-групповых не контролируются. Я правил сложно-групповую с "213" на "245" и спокойно загружал игру. Всего сумма стрелок в игре - 48. 29 обычных, 18 - групповых, 1- сложно-групповая (лежит в Лангепасе на севере).
Групповые стрелки резко упрощают построение станций в игре. Считается что весь парк обслуживается одной-единственной стрелкой. Как это выглядит, смотрите мое сообщение от 19.11.2023.
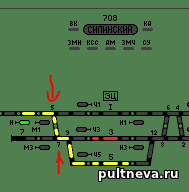
Обычная стрелка может фигурировать в нескольких местах. Обычно в съездах между путями обе стрелки имеют один и тот же индекс. 5я и 7я стрелки Силинского имеют один индекс - "19я стрелка". Это упрощает построение поездных и маневровых маршрутов
Четвертая строка — количество групповых стрелок по участковым станциям. Это группоые 100..118 (без 113й) и сложно-групповая - 213я.
Пятая строка — количество электрических секций путей. Оно записано в шестнадцатеричном формате и на участке Сургут—НВ1 равно 180h (или 384 в десятичной) . Но! Секции могут иметь номера от 1 и до [180h-1=17Fh]. То есть, в заголовке 384, а в реальности будет 383 секции. То же забавный недочет. Вышеупомянутая "19я стрелка" лежит на двух электрических секциях - 111h и 112h. Когда она в обоих ипостясях "прямо" на параллельных путях можно собрать два маршрута - с перегона на станцию и в тупик со станции.
Шестая, седьмая, восьмая, девятая и десятые строки - самоочевидные, даже нечего обсуждать. Можно сократить расстояние между станциями на ГИДе заменив "7" на "5". Покрасить ГИД в в белый заменив "1" на "0" и т.п. Но! Есть одна особенность. Если перебьете год на 2011й и ранее, то у вас пропадет возможность с Ульт-Ягуна отправить поезда со второго и восьмого пути на север и обратно. Там будет ограничение в четыре пути - 7, 3, 5, 1й. Только они могут ехать на север. Это "зашито" внутри проги.
Одиннадцатая и двенадцатые - "минимальное/максимальное время на расформирование" - действует для для НВ1. В Сургуте все поезда расформировываются за два часа, тоже забито где-то в коде.
Добавлено (24.11.2023, 01:09) --------------------------------------------- Вернувшись в прошлое, я бы начал с загрузки графа секций путей из секции data.dat [Data_Sl_Sekz]. Это база игры. С ним можно играться даже не имея никакой другой инфы. Давно можно было бы что-то такое запустить.
Но так как я не в прошлом, то загрузку данной секцию Data_Sl_Sekz я дописал ток сегодня
Добавлено (25.11.2023, 00:50) --------------------------------------------- Поговорим о главной секции data.dat: Data_Sl_Sekz.
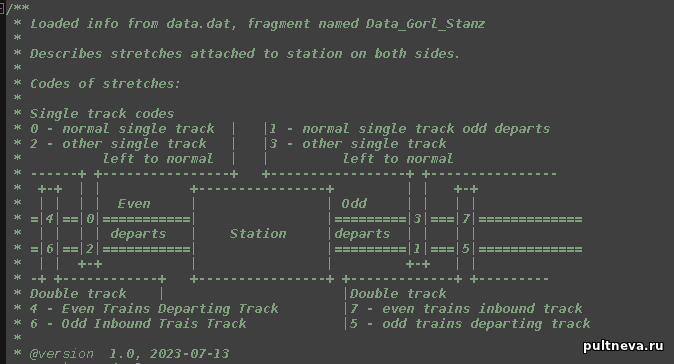
[Data_Sl_Sekz] ; данные о следующей секции, длине, светофоpе для Ч и Н напpавлений и скорости ; 1 - нечетное направление - номер стрелки (0 - нет, >100 группа стрелок) ; 2 - нечетное направление - cледующая секция или блок-участок прямо (0 - нет) ; 3 - нечетное направление - cледующая секция или блок-участок набок (если есть стрелка, 0 - нет) ; 4 - четное направление - номер стрелки (0 - нет, >100 группа стрелок) ; 5 - четное направление - cледующая секция или блок-участок прямо (0 - нет) ; 6 - четное направление - cледующая секция или блок-участок набок (если есть стрелка, 0 - нет) ; 7 - длина прямо (0 - нет) ; 8 - длина набок (если есть стрелка, 0 - нет) ; 9 - номер лампы повторителя светофора Н (0 - нет) ; 10 - номер лампы повторителя светофора Ч (0 - нет) ; 11 - cкорость прямо пасс (0 - нет) ; 12 - cкорость прямо груз (0 - нет) ; 13 - cкорость набок (если есть стрелка, 0 - нет) ; (количество строк должно соответствовать количеству секций в 5-й строке) 0, 0010h, 0, 0, 0009h, 0, 1000, 0, 608, 271, 40, 40, 0 ; 1 ..... 0, 017Bh, 0, 0, 0160h, 0, 200, 0, 0, 0, 80, 70, 0 ; 17C 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ; 17D 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ; 17E 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ; 17F
Выше я рассказывал, что тут сидит caveat, который требуется учитывать при разработке датки: количество секций в строке 5 заголовка должно быть на одно больше, чем количество реальных секций. В 5й строке полигона НВ1 указано 180h секций, но в самом коде их [1..17F], на единичку меньше. В том, что я пишу, эта "фича" учитывается: и недостаток строк, и их избыток будет маркирован как ошибка. (оффтоп. Вот с этим я очень долго мучился исходя из специфики как у меня устроено тестирование, заслуживает отдельной темы.)
Что интересно, в самом описании тоже сидит неточность. В заголовке указано, что 1, 2, 3 колонки - нечетное направление, а 4, 5, 6, - четное, но в реальности там наоборот: четные поезда едут справа налево, т.е. в "нечетном направлении"; а нечетные поезда - слева-направо, т.е. в "четном".
Тут я несколько дней думал над вопросами, который возник из той идеи, что почти всегд пульты, что я видел, сделаны так, что четные едут слева-направо, а нечетные - справа-налево, а у нас - наоборот. Вон, даже если посмотреть на видео, что я постил от 05.06.2023, то там видно, что 2й путь идет слева-направо, а 1й - справа-налево. Но! Это не факт =) Начав гуглить я нашел видео, где четные тоже едут налево: $IMAGE1$
https://www.youtube.com/watch?v=DhNe6SrIEMI
В общем, пульты бывают разные, и направлены могут быть в разные стороны (и это мы еще не думаем о петлях и треугольниках и смене номера поезда четный-нечетный!). По идее, сложности "нарисовать" движение в обратном порядке нет. Но мозг будет "выносить" будь здоров! В каждой секции есть выход "налево" в четном направлении (в НВ1) и направо - в нечетном. Если "рисовать" пульт направления - "четные вправо!" - то можно будет рехнуться: выход с секции будет "налево", но движение пойдет направо.
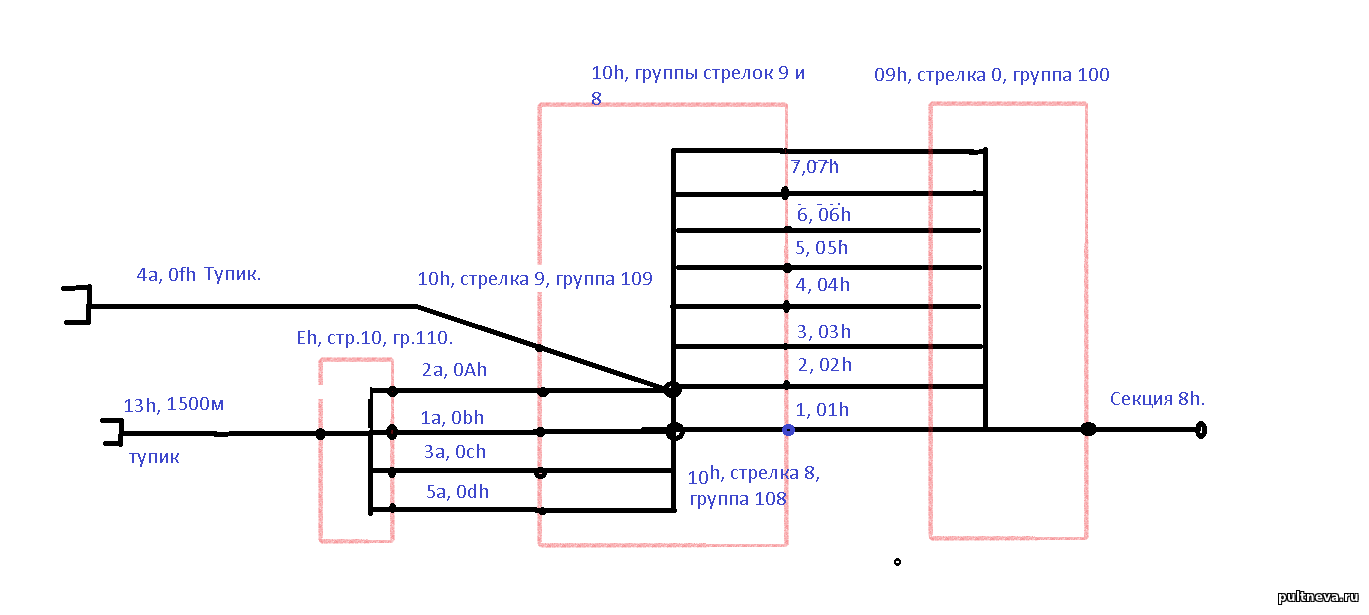
"Налево" у нас секция 0010h, "направо" - секция 0009h. Первая секция - это главный путь грузового парка НВ1. Слева - северная (точней - восточная) группа стрелок, что ведет в пассажирский, справа - западная группа стрелок, что ведет к НВ2. $IMAGE2$
Если мы "рисуем" "четные налево" (как у Zork) картинка секций будет очень легкой: $IMAGE3$ А если рисуем пульт "Четные направо", то картинка секций уже будет выглядеть вот так:
$IMAGE4$ Или "проще рехнуться!" Пришлось думать.... (продолжение следует...)
Итак, я принял решение, что в Data_Sl_Sekz есть не "четная сторона" или "нечетная сторона", а "лево" и "право" и эти "право" и "лево" отражают движение влево или вправо по пульту, а четное оно или нечетное, надо разбираться как-то по другому.
Дальше возникла следующая проблема. В data.dat есть секция, которая описывает перегоны - [Data_Graph_Peregon]. И вот там, каждый перегон указывается блок-участком с четной стороны перегона, перед входным светофором Ч. А длина перегона определяется лампочками: Пример строки:
Это перегон с НВ1 на НВ2, первая секция ("опорная") перегона примыкает к НВ1, ее номер 0017h, на перегоне 4 блок-участка, описанные лампами 158, 159, 160, 161. И снова тот же вопрос: "Как сим будет разбираться куда двигаться?"
Один разраб написишет перегон "Четные вправо", и укажет секцию. Но она справа, и сим для анализа должен двигаться влево по секциям. А другой сделал "четные влево" и там сим при анализе секций должен "ехать" влево. Чтобы решить проблему, были мысли и сздать другой тип графа, типа [Data_Sl_Sekz_R] типа для "правых" графиков. Думал и над вариантом "интеллектуального" анализа, когда сим анализирует в две стороны от опорной секции и так опредлеяет, куда идет перегон и т.п.
Но потом понял, что правило надо аналогичным образом поменять. Теперь в Data_Graph_Peregon опорная секция всегда должна указываться слева и сим всегда едет "направо", вне зависимости четный пульт у нас или нечетный.
Но всё таки оставался последний вопрос - "А как сим-то сможет понять, куда едут четные поезда?" Решение нашлось еще в одной секции data.dat - [Data_Put]. В этой секции data.dat описываются пути приема-отправления по станциям, секции путей приема-отправления, классификация путей и т.п. И вот тут уже все забито жестко: стандарт ГИД "четные едут наверх, нечетные - вниз". Собрав сведения из Data_Put, можно уже четко и однозначно понять как расположены станции относительно друг друга, а значит - где какое направление на перегонах четное или нечетное. А из переговнов можно уже выяснить и ориентацию каждой отдельной секции.
Вопрос с "петлями" и "треугольниками" тоже решаемый: при формировании петли(треугольника) один "левый"("правый") конец придется соединить с "левым"("правым") концом другой секции.Сим сможет понять, Что тут происходит "смена" номера поезда с четного на нечетный.
Еще некоторое время потратил, размышляя над ситуацией, когда выход со станции на перегон меняет номер поезда с четного на нечетный. Это ситуациа станции Шарташ, где проходит основной путь Екат - Шарташ - Тюмень, и откуда в четном направлении уходит ветка с переключением на нечетный номер на Челябинск, так как ветка Шарташ — Уктус — Челябинск — нечетная. Итогом размышлений стал вывод, что если перегон не обозначен на графиках, то и пофиг, что поезд меняет номер! Главное, что он отправился с Шарташа четным на восток, а то, что он тут же сменит номер на нечетный, нас волновать не будет если только мы не решим рисовать график ГИД направления на Челябинск. "Мы отправили четным, остальное нас не волнует!" А вот если мы рисуем ответвление на Челябинск, то на этом графике Шарташ будет сверху, Уктус ниже, а значит — конкретно на этом графике сим отрисует этот поезд уже нечетным номером.
Добавлено (28.11.2023, 16:39) --------------------------------------------- Что-то вот я неправильно делаю... В загрузку Data_Sl_Sekz я решил добавить проверку переполнения/исчерпания так как читается оно в формате 32-bit int, а сохраняется в формате 16-bit short (для экономии места). Тест для проверки переполения я писал 55 минут, а сам код, который и должен выявлять переполнение - 5 минут. Как-то пока что выглядит не очень адекватно, когда код пишем 5 минут, а тесты под него - 55 минут.
Добавлено (05.12.2023, 04:16) --------------------------------------------- Технически играл в своем симе версии 0.0.0 на южном участке, Сургут - Куть-Ях. С обычного пульта Нева я как бы передаю поезда на южный участок и провожу уже по передаче. На север передачи, конечно, так просто не получается сделать, оно само генерирует. На южном я стараюсь "подвести" поезда вовремя, чтобы на Неве забрать на север максимально состыковавшись. "лишние поезда" генерирует южный участок, в пульте автогенерацию отключил. Но сгенерированные с севера провожу по пульту и передаю на юг как обычную "передачу", а сгенерированные с юга провожу с юга и передаю на Пульт Нева ручной генерацией. Немного через ж... получается, но играбельно.
Кому надоело играть в Неву "типовым" способом, могут попробовать поиграть "нетиповым". В любом онлайн генераторе случайных чисел генерируете время появления "внеочередного" поезда. А потом этот поезд пытаетесь "встроить" в график в data.dat. Если на севере это легко, то на юге это будет весьма нетривиальной задачей. Это не работа диспетчера, скорей это работа "графиста". Но тоже некое развлечение.
Можете сгенерировать "пакет поездов" тулзой, что приложил. DSim.zip копируем в новую папку, распаковываем. Там будет startup.bat. Кликаем, запускаем. Если напишет что-то типа "DSim v.0.0.0.0" и ниже восемь строк со случайным временем суток, значит все отработало штатно. Можно брать и пытаться на Куть-Ях "впулить" эти восемь поездов в расписание, в это время, 4е первых - как четные с Куть-Яха, 4 нижние - как нечетные с Сургута.. Если не отработало, что может говорить, что Java нет, то можно скачать jdk0.zip и распаковать в той же папке и снова запусить startup.bat.
Да не! он просто кидает случайно время в течении суток, в которое можно считать что нам дали грузовые доппоезда. И игра заключается в том, чтобы эти доппоезда "вписать" в график.
Вот как пример я тут "добавлял" поезда на НВ1-Сургут: http://pultneva.ru/forum/2-345-16013-16-1702376056
Прикладываю чертеж для игры "на бумаге" на участке Куть-Ях — Сургут. Чтобы распечатать чертеж, рекомендую использовать бесплатный КОМПАС-3D viewer. Его можно скачать тут: https://kompas.ru/kompas-3d-viewer/download/
Открыв прогу и загрузив чертеж, нажимаем "предпросмотр":
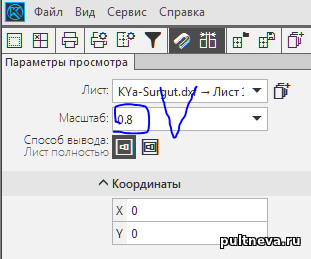
В предпросмотре выбираем масштаб 0.8, тогда чертеж "ляжет" на 6 листов А4:
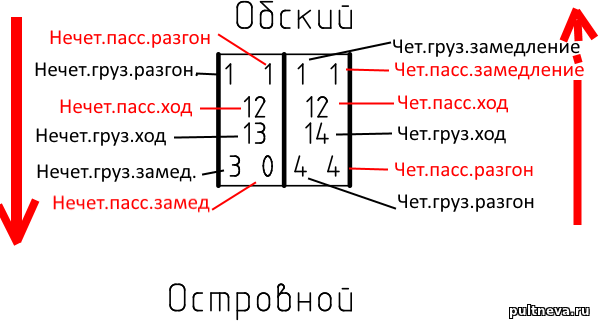
В чертеже пробиты перегонные хода поездов. Расшифровка:
Если мы ведем грузовой ходом с Островного на Обский, то это четный, будет идти 14 минут. С разгоном с Островного это будет 4+14 = 18 минут, а с разгоном и состановкой по Обскому 4 + 14 + 1 = 19 минут.
Как играть? можно взять мою прогу выше, сгенерировать время для 8 дополнительных поездов и попробовать "провести" все поезда расписания + доп.поезда по графику, по возможности не сломав движение никому графиковому.











 За два часа работы.
За два часа работы.